- 2023-12-06 10:21
- 作者:佚名
- 来源:InterSystems
InterSystems开发者社区汇集了大量有用、有趣的实践探讨,我们会不定期精选文章,供您参考借鉴。
本文篇幅较长,描述了卫生信息互操作标准的要素、发展历史、卫生信息数字化转型对卫生信息互操作标准的挑战等,此处3000余字,仅为部分内容摘选,欢迎点击“阅读原文”,移步InterSystems开发者社区(中文版)查看原文,参与讨论。
原文@Qiao Peng
卫生信息和其它信息化一样,经历了数码化、数字化到当今的数字化转型,卫生信息互操作一直伴随左右。
数码化(digitization):国内90年代开始,HIS全面铺开,卫生信息进入数码化时代。数码化初期业务集中在HIS上,互操作需求不高,点对点接口可以满足绝大多数需求。
数字化(digitalization):在2000年之后,各种专科系统、尤其是电子病历的诞生,医保和新农合的实施,要求卫生信息共享交换,以提高流程自动化水平。互操作需求爆发,2007年集成平台开始进入市场,卫生信息化进入数字化时代。
数字化转型(digital transformation):2014年,国内正式进入移动互联网时代;次年《全国医疗卫生服务体系规划纲要(2015—2020年)》发布,卫生信息化的服务对象(服务于医护技到服务于患者)和业务形态(临床管理到患者服务)都发生了翻天覆地的变化,开始步入数字化转型的时代。它对互操作提出了更高的要求——利用互操作,增强全员参与,为卫生服务创造新价值、发展新业务,推动医疗机构持续数字化转型。
可以说,卫生信息互操作在整个的卫生信息产业中愈发重要。
国际卫生信息互操作发展了30年,国内也发展了20年,但卫生信息互操作依然是一个挑战。
知史而明鉴,识古而知今。我们看看国际卫生信息互操作发展的历程,对未来的卫生信息互操作有什么借鉴。
卫生信息互操作标准的要素
HIMSS把信息互操作/集成定为4个不同的级别:
- 基础级别,仅仅打通了系统间进行数据通讯的通道。
- 结构级别,在基础级别上,定义了数据交换的格式和语法。
- 语义级别,建立在行业通用的基础模型和数据编码上,使用标准化的行业语义来定义数据元素,使用标准的值集。因此语义级别的互操作是全行业可以理解并有确定行业意义的互操作级别。或者说语义级别的互操作才是基于标准的互操作。
- 组织级别,通常都是由国家、行业协会和行业标准开发组织开发的。它加入了政策、社区、法律等方面的考虑,分析了通用的业务流程和工作流,在此基础上设定了参与互操作各方的角色、权限,服务和知情同意策略等。我们的互联互通,就是组织级别的互操作。
目前的卫生信息互操作项目多数停留在结构级别。只有达到语义级别的信息互操作/集成,才是标准化的信息互操作/集成,才能降低实施成本和提高实施效率。
做到语义级别的互操作标准并不容易,首先是消除语义歧义、其次行业普遍认可、再次是要覆盖行业用例并具有适应行业不断变化需求的弹性。

图片来源:EuroVulcan Conference 2023
先说消除语义歧义。要在信息交换时消除语义歧义,需要在语言、语法、词义、句法等多方面努力,而且涉及到数据的颗粒度。尤其在医疗行业,完整、消除歧义才能保障卫生信息准确和医疗行为安全!
HIMSS认为要消除语义歧义、达到语义级互操作性,需要基于五位一体的语义标准,包含:
- 词汇/术语标准:依靠结构化的词汇、术语、代码集和分类系统来表示健康概念。例如ICD-10、SNOMED-CT、LOINC、RxNorm是行业里典型的词汇和术语标准。
- 内容标准:描述信息交换中,数据内容的结构和组织。而HL7 CDA、HL7 V2、C-CDA都是行业内容标准。
- 传输标准:定义了计算机系统、文档架构、临床模板、用户界面和患者数据链接之间交换的消息格式和传输方式。传输方式确定了卫生信息交换的“推”和“拉”方式。DICOM、IHE等都是传输标准。
- 隐私和安全标准:是确定谁、何时、出于何种目的、使用哪种个人健康信息的权利,以及如何保护健康信息的机密性、可用性和完整性的标准。美国的HIPAA和欧洲的GDPR都是关于隐私和安全的标准。
- 标识符标准:是用来唯一标识患者、机构、医护技、设备等实体的方法。例如咱们互联互通里用到的OID和美国的护士标识NCSBN ID…
并非消除了语义歧义的标准就能被广泛接受和认可,需要行业标准化组织的推动,实现厂商中立,毕竟互相竞争的厂商很难接受对方的企业标准。回顾一下行业里流行的标准,无论是术语标准、还是消息和文档标准,都是行业里标准化组织发布的,其中最有名的就是HL7。
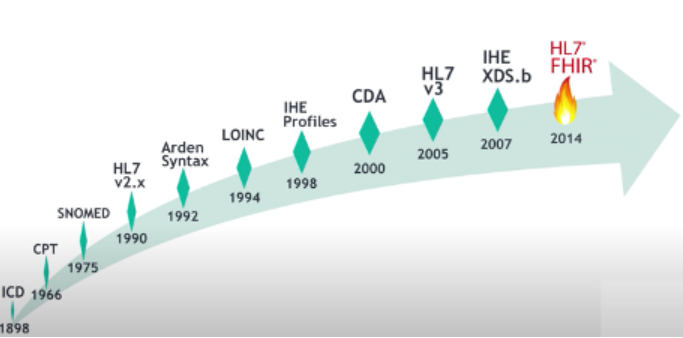
从这个行业标准发展史可以看到,毫无例外的,标准先从术语标准开始,例如ICD、SNOMED,历史都非常久远。而我们常用的HL7 V2有30多年历史了,CDA和V3也20年左右了。从2014年,HL7推出了FHIR。这些标准是为何以及如何演进的?
互操作标准发展要满足不断变化的行业需求和用例
先看看90年代初的互操作的业务环境,就像下图那么简单:医疗机构还处在数码化向数字化转换的时代——HIS等业务系统开始大规模部署以实现流程和数据的数码化,同时产生了非常有限的跨业务系统的流程自动化——信息集成需求。实时卫生信息交换的需求基本都在医疗机构内部(局域网,那时候www刚诞生),而院内的业务系统数量非常有限、且系统边界清晰,使用的用户基本就是医护技和管理人员,需要的互操作流量规模可以准确预测。而且系统互操作的技术手段非常有限,基本就是文件传输、串并口、socket,而SOAP(2000年)、RESTful(2000年)、甚至HTTP(1996年)等协议都还没有产生。
HL7 V2
这就是HL7 V2消息交换标准产生的时代,和所面临的互操作业务需求:它将业务事件和业务事件的上下文封装在消息结构中,在系统边界中传递这些消息。
业务系统边界清晰,一般用消息引擎来路由和转发这些消息,从而不打破系统边界。各个业务系统只要能接收/发送并处理这些标准化的消息即可。
近距离看一个HL7 V2消息示例,它是一个由多种分隔符分割的字符串,由区段和字段构成:区段是一组分类的数据,例如PID是患者信息区段;而字段是每个数据项,例如患者标识(在PID区段里)是“1182594^^^系联医院&1^^系联医院&1”,它本身也是一个结构,用于放标识符(1182594)和标识分配机构(系联医院)等信息。
而事件就是消息头区段里的ORM^O01,其中ORM代表业务域”通用医嘱消息”,O01代表事件“医嘱请求”。
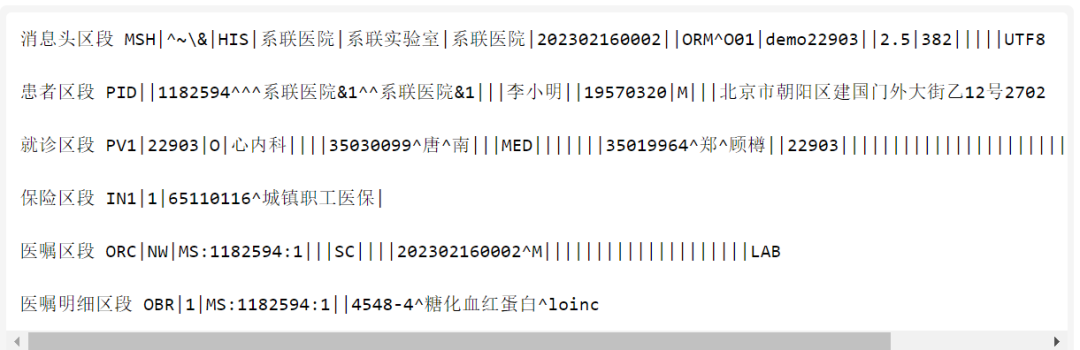
注:此处为不完整截图,请阅读原文查看完整内容
为什么HL7 V2会是这种难读的格式?因为它是窄带时代的产物,当时通讯带宽有限,数据格式需要紧凑,通常仅用分隔符分割,以减少传输的数据量(相较XML,通常能减少80%以上的数据),如今在一些检验检查设备的通讯协议中还能看到类似的设计。同时,从早期直到现在,多数HL7 V2消息是通过socket交换的。这些特征都是90年代互操作的历史印记。
HL7 V2是按模式复用的角度设计的颗粒度,也就是说它的颗粒度是信息区段。但并不是所有的信息区段都有独立的含义和复用的价值,例如区段TQ1、TQ2定义服药时间和用药途径,没有单独存在的可能和直接复用的价值。
另外,V2消息的字段随意性很大,相同内容可以放在不同的字段甚至区段里面;用户还被鼓励创建自定义的Z区段进行消息体扩展。也就是说它标准化程度不高,需要实施的双方事先约定好数据具体怎么放才能实现信息交换。同时V2术语约束机制很弱。
HL7 V3 和 CDA
世纪之交,卫生信息化发展提速,电子病历和各种专科系统崛起,更极大推动了卫生信息的交换和流程自动化的需求,同时对交换的语义标准化程度有了更高的要求。这需要更严谨的互操作业务抽象和术语约束。卫生信息正式进入数字化时代,也正是在这一时期,诞生了包括IHE、CDA、HL7 V3在内的众多互操作标准。
从模型抽象的角度看,应该全面包含用例模型、信息模型和交互模型,但V2的关注点基本在交互层面,对其它层面的抽象很弱。
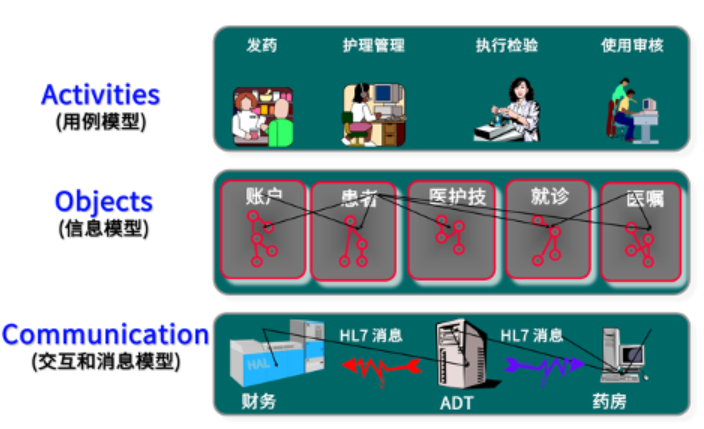
由此,携着其著名的参考信息模型(RIM)方法论,V3在2005年横空出世,对业务场景进行分析,抽象交互逻辑,从参考信息模型到领域信息模型,再到精细化消息信息模型,最终产生需要的消息模型。模型以XML进行序列化,相较于V2,进步了许多。
这套方法论产生的V3消息标准化程度很高。但为了覆盖所有业务需求,RIM是高度抽象的(难于理解的);同时V3方法论是“按约束设计”(design by constraint),试图涵盖所有应用场景,避免自定义扩展,这使其越来越复杂、越来越庞大,而且用户没有RIM基础很难自己对其扩展,从一个极端走向另一个极端。
V3的高复杂性和高使用门槛,造成了它事实上的失败,没有成为V2的替代者,就像一些专家评论的——“RIM创建了语义互操作性,但没有创建临床互操作性“。
注意,国内有一些实践中,甚至没有严格遵循V3发布的XML schema,直接用代码拼出XML字符串,也不做消息校验,这不算标准的V3。
同样在世纪之交,很多业务需要即时性不那么强、但数据更完整的交换——小结性质的临床文档交换。在这个领域,最主流的是CDA临床文档架构标准。CDA源于1996年就开始的临床文档中结构化标记工作,并在1997年并入HL7,随后使用V3参考信息模型来完善和发展。大家可能注意到前面的图上CDA早于V3发布,就是这个原因。
CDA临床文档架构,用于描述结构化文档,同时允许插入供人类解读的非结构化部分。它产生的文档具有上下文完整、可持久保存、可管理、可认证等特性。CDA文档和衍生的CCD文档广泛用于医疗机构边界间和医疗系统边界间的文档交换,或作为具有法律效力的临床文档依据保存在文档仓库。
CDA是成功的,可能是V3基础上唯一成功的部分,但它不能解决细数据颗粒度访问的需求。
- 分享到:


