- 2017-09-29 11:27
- 作者:Jeremy Howard
- 来源:Hacker Noon
这篇文章中,Howard认真谈了谈AI对整个医疗行业的各方从业者的影响。精彩,且不容错过。

Howard在TED上的演讲
贯穿整个人类史,医学一直是门自带艺术气质的学科。相较于建立一套标准的诊断治疗流程,医学的重点一直在每个医生的技巧和经验上。
虽然近年来,实证医学(EBM)和精准医学的先驱已经向医疗领域注入数据驱动的严谨实践,上面的情景已经改变。但是,大多数医疗观念还是公元前希波克拉底学说的延伸。

古希腊公元前医师希波克拉底雕像
他建立了健康和疾病的平衡学说
那目前的医疗现状如何呢?事实上,世界人口稠密地区的实际医生数量不足需求十分之一,需要百年时间才能填补。不仅医务人员缺口大,并且医疗水平有限。误诊、延诊和过度诊断造成数百万病患死亡和数百亿资金的流失。
好在我们有科技。技术给医护人员和病患提供所需的准确信息,偏远地区的医务工作者看到世界各地的医疗研究,让发达地区的医生诊断更高效准确,在医疗诊断中更方便地了解病人及亲属。
这股医疗科技的中坚力量就是人工智能。尤其是深度学习,已经成为一种强有力的检测工具,在医学影像领域表现惊人。比如谷歌的视网膜病变诊断系统、斯坦福的AI诊断皮肤病算法、Enlitic将深度学习运用到癌症等结节检测里。
放眼整个AI医疗布局,患者、医务工作者和数据科学家都面临着怎样的机遇和挑战?未来的医疗形势怎样?那就接着往下看——
挑战
标记过的历史数据
有种广为流传的普遍说法是,深度学习算法需要大量数据才有效,这种说法不一定是对的。举例来说,Enlitic的肺癌算法只扫描了1000多名癌症患者的数据,尽管数据集很小,但它具有有效建模的关键特征:
首先,数据集中包含了每个病人至少三年的年度扫描数据,在构建诊断算法时,病情随时间的变化情况至关重要。
其次,数据中包含了放射科医生提供的诊断意见,里面包含肺部结节的位置,算法可以从中快速找到重要信息。
最后,数据集中包含确诊肺癌三年后每个病人的康复情况,能够说明患者存活率等信息,帮助构建诊断系统。
这个项目无法显示的信息也可能很实用,比如医生的治疗建议。因为数据集中不包含对病人的治疗干预及病患反应等纵向数据,因此构建的算法只对诊断有效,不牵扯治疗计划。
目前,传统检测方法仍无法发现肺部40毫米大小的结节,因此肺癌患者死亡率高达90%。惊喜的是,Enlitic开发的系统能发现小于5毫米的结节,使患者的生存率能增加10倍。
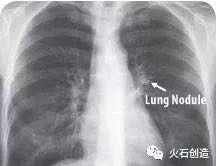
图中箭头所指为肺结节(Lung Nodule)
目前,这些医疗数据信息还零散地分布在多个机构中的不同部门中。不知我们还要多久才能实现跨地区医疗记录整合,可以将多年内所有的检测、诊断及治疗措施全部包含在里面。
法律保守主义
不管数据是集中获取还是多来源拼凑起来的,一般来说,数据持有机构对将数据共享给数据科学家还非常谨慎。据司法人员透露,泄露病患隐私可能会终结数据科学家的职业生涯,还会连带机构损失数百万美元。
那么,病人是如何看待分享私人数据的呢?在被问及如果将来可能帮到他人,是否愿意分享自己的数据时,大多数病人欣然同意——特别是听说可能会为自己将来的治疗带来更好选择时。
患者的新机遇
病人可控的数据
患者有个很清晰的机遇可以选择:即从不同渠道收集自己的医疗数据,包括可穿戴设备、自我报告等。数据科学家和机构可以让病人自己选择将数据分享给哪些数据科学家或项目,给他们一个安全的数据环境。作为回报,他们可以为患者提供:
提前享受到医学最新突破的治疗
财物补贴
数据怎样被利用帮助其他患者的信息
这是患有罕见或无法治疗疾病的患者家属的新机会:联合其他情况相似的病人提供各种数据。越多病人加入数据共享,越可能尽快发现疾病的关键信息。
区块链
不同数据的重要性不能一概而论。
罕见疾病患者的数据对治疗至关重要,多年长期观测的数据比短时间内的数据更具价值。这就会带来一些潜在问题,比如有人想通过伪造数据获得报酬。
区块链技术能让医疗数据记录变得清晰可查找。根据这一记录,数据提供者可根据数据实用程度获得奖励。因此,病人提供的数据越完整、准确、相关,报酬就越高。
这也为机构提供了一些有趣的机会。获得病人许可的机构可为研究人员提供完整的数据集,从中获得财物或技术回报。从长期看,病人可以授权机构通过区块链将数据传递给数据科学家。
科学家的机会
数据科学家都希望拿数据做些有意义的事,但只有少数人有这样的机会,大部分对口工作集中在广告技术、对冲基金交易和产品推荐领域。
数据科学家的挑战通常包括寻找数据获取途径、了解待解决问题、提供可实现的解决方法。
为了让数据更实用,他们需要进行一系列处理,在实践中这些步骤通常重复多次:
数据清理
探索性数据分析(EDA)
创建验证集
构建模型
分析并检验模型
为了完成上述步骤,数据科学家需要一个丰富的分析环境,在里面可以选择他们的工具、库、可视化解决方案。目前,大多数人用的是R语言或Python。
通过提供预装数据和环境,数据科学家能快速找到有意义的数据。也可能是多人独立处理一个问题,根据工作效果分得奖励。
AI医疗来袭
数据收集
我们需要赋予每个病人收集和维护个人医疗数据的能力,包括:
实验室的检测和影像学研究
诊断
用药处方
非处方药和补充剂
其他医疗干预措施
饮食和锻炼记录
家族病史(理想情况下,自动通过链接家庭成员自动维护这些数据)自我报告进展,比如精力水平、幸福感等。
基因组学和其他测试
这意味着患者数据也可以从医疗服务提供者那下载。不论是来自用户还是服务提供者的数据,都需要在计划开始时下载一次,之后可以用API定期追踪患者情况,或者用各种可穿戴设备的APP获取他们的数据了。
数据分享
每个病患都需要处理他们收到的数据请求,请求一旦增多,病人处理每个单独请求也会很麻烦。在这种情况下,我们可以为病人设置接收规则,自动判断接受、拒绝还是需要人工干预。
每份数据都需用能溯源的方式打上来源标签。当然,一些医疗数据存储量很大,它不一定被存储在病人的设备上。
一旦患者允许项目访问他们的数据,这些数据就需要对研究者公开。研究人员需要的分析环境要足够丰富。这将向他们展示问题的全面信息,并展示如何访问项目数据。
巨大的机会
让病人控制数据,让数据科学家有地方施展拳脚是个不错的想法。
还有一个更大的机会,即当模型可被持续更新时时,将所有的模型组合在一起。每个数据科学家的特征工程步骤可被保存,并提供给后续研究使用(当被复用时,他们将得到奖励)。此外,他们预先训练的模型激活函数可被自动引入新模型预测能力是否提升。
让新数据持续提升现有模型需要所有数据源的含义和格式相同。虽然这很复杂,但有经验的数据产品经理需要有先前经验预先确定数据源格式或语义的更改,并且持续测试模型。
通过复用预先训练的模型,我们从组合数据集中受益,且没有任何逻辑或隐私问题。
这也意味着我们也可以高效攻破数据量稀少的罕见疾病和儿科疾病。在这些情况中,可用预训练模型分析数据,只需要很少的参数就能组合它们。
随着医疗行业的进步,这种收集和分析数据的方法将带来新的见解,并为医务工作者和患者提供所需信息的清晰集合。
- 分享到:


