- 2016-04-13 10:13
- 作者:刘涌
- 来源:36氪
“我希望能和互联网创新公司合作,来打造一个 ‘临床遗传机器医生’,解决罕见遗传病的诊断难题,当然这还需要基因测序公司和临床遗传学家的参与。只要你输入收集到的各种基因型和表型,‘临床遗传机器医生’ 就可以马上帮你做出准确的诊断,并为下一步的处理给出最合理的建议和提示。”
今年3月底,上海市第一妇婴保健院院长段涛在他的个人微信订阅号“段涛大夫” 里面,发布了一篇院长日记《令人失望的互联网创新》。上面那段话是这篇文章的结尾,也是段涛提出的一个挑战,希望那些有创新基因的公司能够完成这个挑战。
当天,春雨医生 CEO 张锐在自己的朋友圈里表态:“段院长的挑战,春雨来接!” 张锐认为:“未来三年,是 AR 和生物医学工程聚合、裂变的大好时机。技术的创新才是源创新,春雨一直在做 ‘人脑训练电脑’ 的浅层医学人工智能,应用在我们的用户自诊和智能分诊两个板块,每年节约我们的人力成本不低于 1000 万,现在是时候朝着更专业的医疗纵深挺进了!”

这场隔空对话,展示了医疗领域中最先进的头脑对医疗大数据未来应用的想象。
确实,当 AlphaGo 大放异彩时,人工智能确实带给各个领域太多想象空间。尤其是在医疗领域,当 Watson 机器人在疾病诊断领域的能力已经可以媲美普通医生,它也许值得人们付出更多的金钱、精力以及激情去做更多探索。
故事.版本一
医疗人工智能的基础,是医疗大数据的挖掘和应用。有关医疗大数据,这是这几年互联网医疗领域流传最广的故事。虽然每一家创业公司的模式千差万别,但无一例外都会有一条:对大数据的挖掘和应用,虽然关于如何实现的部分往往语焉不详。这充分反映了两个问题:所有人都意识到了医疗大数据开发的价值,但开发的路径却难度很高。
于是,我们听到的第一代医疗大数据的故事就变成了以下这个样子:
①有关数据来源
中国互联网医疗可以说是白手起家,至今为止仍然不受传统医疗体系待见。所以,早期的医疗大数据基本上都只能来自互联网医疗公司自身的积累。这里的 “早期” 既指时间上的早期,又包括开发思路上的早期。那么,早期的数据来源大概有这么几类(欢迎补充):
在线咨询类公司——这类公司既有综合型的,又有垂直型的。数据积累的方式上主要是通过医患在线问诊的方式,建立患者个人的电子健康档案;
智能硬件类公司——纯粹的智能硬件在医疗领域的应用日渐式微,但越来越多的医疗服务开始结合智能硬件,比如血糖、血压、体温、心律等,数据积累方式主要是对用户体征数据的检测;
基因检测类公司——基因检测在近两年日 趋火爆,主要是受到检测成本降低和精准医疗的推动,门槛大大降低,使得越来越多的普通用户能够消费基因检测。
科研工具类公司——虽然与医患资源类公司一样是收集患者的疾病数据,但科研类公司收集数据的形式、应用明显不同,科研机构在数据积累过程中发挥了主导作用。

②有关数据应用
在医疗大数据版本一的故事里面,之所以是早期,主要是还是因为开发利用方式的早期。在这个阶段,虽然关于医疗大数据、人工智能已经有了概念,但在此时能接受这样故事的人毕竟还太少,也太遥远。于是,版本一里面应用医疗大数据的方式基本有这么积累:
服务于医疗本身——长期以来,患者个人是不掌握自己的医疗数据的。互联网医疗出现后,用户可以通过手机来收集自己的健康数据,帮助医生更好的了解自身的健康历史;
服务于医药企业——药企对数据的需求既强烈又多元,包括市场营销需求、新药研发需求、应用反馈需求等。因此,鉴于药企买单欲望强烈,很多数据应用商都主动向药企考虑;
服务于保险公司——这一点中美有些差异,美国保险公司对数据的应用主要是对医疗服务质量和费用的控制,而在我国,保险公司对数据的应用则主要是设计新的保险产品。
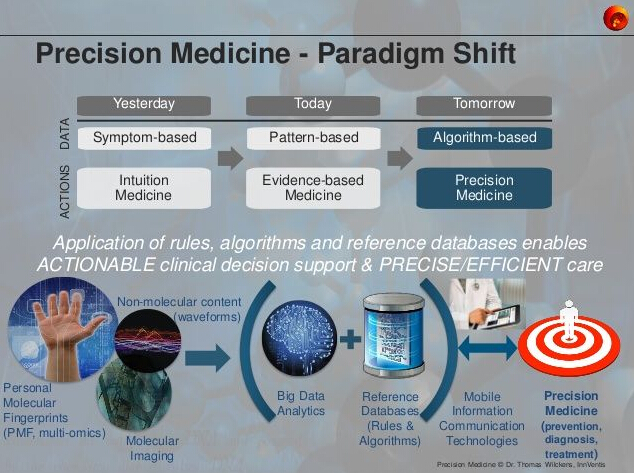
③有关应用现状
其实在版本一的故事里,已经有一些有了很好的应用效果,比如药物警戒,用医疗数据来弥补临床数据的缺陷,及时反馈药品不良反应、治疗效果等;再比如保险控费,用医疗大数据控制服务质量和费用,控制和减少保险欺诈行为等。这些领域之所有比较好的应用,主要是因为药企和保险公司的商业驱动力更强。当然,这也仅是在美国。
虽然我们前面罗列了不少有关医疗数据的来源和积累,但实际当中,这些案例都或多或少存在着问题。甚至由于这些问题的存在,版本一里面这些比较浅层次的数据应用都还处于非常遥远的阶段。
数据的完整和有效性——互联网医疗毕竟是新兴事物,用户有接受程度和使用习惯的问题,而且硬件设备也存在功能和精准度的问题。这使得数据收集面临着不完整且缺乏连续性的问题,而且大多数硬件设备没有取得医疗资质,采集的数据也无法做医疗级应用。
数据处于割裂的状态——互联网医疗产品主要收集的是患者在医院的健康数据,而对医院内的数据鞭长莫及。加上医院与互联网医疗无法打通,这导致了医疗数据在院内院外割裂存在的状况。而且由于医院本身信息孤岛的问题,患者在不同医院求医的数据也是碎片化存在。
数据规模仍然非常小——作为大数据应用,目前的医疗数据采集规模根本达不到 “大” 的程度。一个是很多创业公司的数据都是从头积累,再一个是市场认知度仍然有限,最典型的就是基因检测,很多公司的样本量还处在几十个、几百个的水平。这使得目前的医疗数据基本无法实现商业化。
当然还有一个问题,段院长在他的文章里也指出了,就是医疗大数据并没有被认真对待,或者说挂羊头卖狗肉。我国的大多数互联网医疗公司打的仍然是医院号源的主意,仍然是一种快速变现的心态,也无怪乎令人感叹,“我们多数的移动医疗创新公司还在拼命的靠补贴靠地推在拉用户,在做挂号黄牛的生意,真的令人很失望。”
故事.版本二
关于医疗大数据,最令人兴奋的应用无疑还是在临床方面。比如时下最热门的精准医疗几乎火到没朋友。但精准医疗因为相对初级还跟数据应用关系不大,主要是取决于两点:要么是技术上取得特别重大的突破,要么是概念上找到特别唬人的方法。另外一个医疗大数据在临床上的应用,则是临床辅助诊断,或者更遥远一点,人工智能医生。
在临床上发挥机器的作用,首先需要对临床数据的有效挖掘利用。传统的公立医院在这一点上是完全指望不上的,根本原因在于没有任何激励机制的存在。而早期医疗大数据的应用之所以对医院敬而远之,主要是开发难度太高。
受限于信息化程度,医院往往处于信息孤岛的封闭状态,内部信息系统有纷繁复杂标准不一,而且有大量的病例数据以纸质状态存在。数据清洗以实现标准化、结构化的难度非常大,而且还需要打通院内院外数据的流动。
当然,这里还必须提到数据安全。美国已经不止一次爆出医疗数据泄露或受到攻击的案例。而来自 Ponemon 推出的一份报告《2013年 数据泄露成本研究》显示,医疗行业的数据泄露成本最高,平均每个患者的医疗信息泄露带来的信息安全管理成本高达 233 美元,远高于零售业的 78 美元。而当大量商业公司在明目张胆的打着靠数据赚钱旗号的时候,临床数据的开发确实需要非常谨慎。
①新数据来源
不过临床数据开发的迟滞,仍然是造成我们的医疗大数据推进缓慢的一个重要因素。所以,在版本二的故事里,我们看到了已经有创业公司努力在临床数据上进行探索。(欢迎补充)
临床数据的聚合——医院内的医疗数据也是分散的,HIS、LIS、PACS 等系统里都储存不同类型的病例数据。因为这些系统来自不同厂商,数据标准不一,医院内部也缺乏完整、连续的数据资料。所以,在医院实现数据聚合成为临床数据开发的一个小前提。已经有创业公司在这方面探索,并得到了资本市场的认可。
临床数据的开放——当然还不是公立医院数据的开放,而且公立医院目前的信息系统也很难支持开放。不过,已经有很多创业公司在尝试临床数据开放,甚至直接开办医院、诊所来重构底层信息系统。再加上很多 SaaS 模式的诊所管理系统的出现,就为医疗数据的共享以及与智能硬件设备的对接创造了条件。
临床数据去中心——很多人相信,医院只是时代的产物,会逐渐消失,所以医疗数据也未必一定要在医疗机构内产生。随着新技术和数据采集方式的进步,包括诊疗数据、研发数据等,都在逐渐突破医疗机构的边界,进入人们的客厅、日常生活。这种数据采集的量和周期,都是医院内数据采集所无法比拟的。
②应用和问题
这些在临床数据开发方面的努力,为未来人工智能的研发创造了可能。恐怕也还只是限于可能,距离真正的应用还有一段距离。当然,在 AlphaGo 完胜李世石以后,人工智能所展示出的进步速度让所有人惊艳。说不定五年后,机器人医生就真的出现在社区诊所了。但是眼下的问题恐怕还是必须要克服:
数据解读——围棋棋盘的可能性毕竟是可以穷尽的,但目前的人工智能还无法解决未知因素的问题。尤其是在医疗领域,不仅是未知因素的问题,甚至还有无知因素的问题。很多因素不仅医疗数据的采集范围之外,更是在人类的认知范围之外。不要说癌症这种人类尚未攻克的疾病,绝大多数疾病都存在着相当多的未知因素。
数据规模——医疗数据的应用前提条件是数据规模要足够大。其实,这一点中国的情况要比美国好多了。比如说,中国一家三甲医院的数据量几乎抵得上美国一个州的量。但问题是,有能力、有条件、有机会开发应用这些数据的机会太少。财大气粗的保险公司在医院面前都毫无谈判能力,遑论弱小的互联网医疗公司。恐怕只能指望高瞻远瞩的医院院长,发挥鲶鱼效应。

数据监管——对于政府监管来说,医疗数据的应用是个新问题。起码至今,究竟医疗数据归谁所有的问题都没有明确。而一旦医疗数据被滥用,危害是极大的。一个非常简单的道理,你的银行卡密码可以修改,但你的基因信息能修改么?虽然现在对基因的解读能力有限,但是只要样本成功采集一次,就可以无限检测。如果你的基因数据泄露了,呵呵呵呵,呵!
最后,可能还是野心的问题。如果已经收集到了一批数据,马上就能商业变现,就能挣大钱,有几个人还愿意去搞什么人工智能么……


