- 2016-11-28 10:56
- 作者:刘帆
- 来源:贝壳社
11月24-25日,由中国医疗器械行业协会智慧及移动医疗分会、医用软件分会联合主办的“第三届中国智慧健康医疗发展高峰论坛”在武汉召开。
北京大学人民医院是国内首家通过HIMSS7级的医院。该院信息中心主任、医学大数据研究中心副主任刘帆到场分享了他在医疗大数据应用、价值挖掘和变现的一些心得体会,贝壳社记者整理了全程干货以飨读者:
医疗数据的商业价值是挖掘出来的
近年来,不少医院投入千万甚至上亿元成本,做信息化建设。但医院是否思考过,医疗信息能用来做什么事?能利用的程度?用来做管理还是做决策?还是要降低成本?提高效率?仅仅是这么简单吗?
信息整合,是利用数据的第一步
过去,我们医院的信息化建设就是由多家公司共同完成的,所以到了2011年到2012年,医院的信息整合面临严峻考验,我们尝试用平台把所有信息整合在一起。
通过平台实现资源、流程和数据的整合后,我们建立了三大数据中心,即前台的临床数据中心(CDR)、后台的运营管理系统(人力资源、财务、固定资产、物流采购库存统一管理的系统),以及医院的影像数据中心。
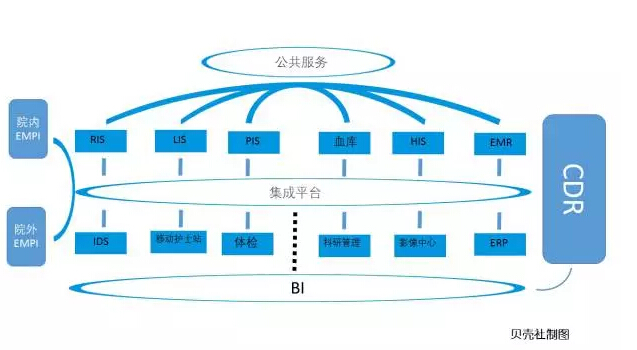
临床数据中心(CDR)
医生最需要临床数据整合。特别是以病人为中心,以其患者索引号(EMPI)和时间轴主线,把所有的临床数据做统一化、标准化、结构化管理的CDR。
现在所有行业都可以用身份证来索引信息,但唯一在医疗行业,还存在卫生部的居民健康卡、人社部的社保卡、城市自己的城市居民健康卡、以及医院自己的就诊卡,造成病人的大量信息无法以唯一的识别号来索引。2014年,国务院提出要建立以身份证为索引的社会信用体系,唯独医疗被排除在外。
因此,CDR最基本的问题是,如何把一个人全生命周期的健康医疗数据串联在一起。2013年,北大人民医院将患者的历史临床数据都迁移到CDR系统中,并做清洗处理。
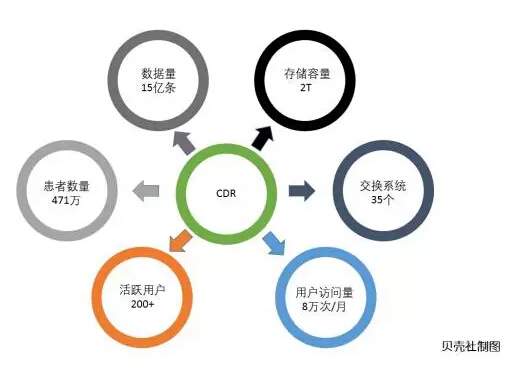
医院患者索引号(EMPI)的作用,就是把历次门急诊、体检、住院中发生的检查、诊断、治疗等信息串联在一起。这样一来,以后产生的数据都是简单化,且标准化的。现在医院已经存储了大约471万患者的数据。下图是北大人民医院CDR目前的使用情况:
影像中心
由于很多学科都以影像为支撑,医院的影像系统非常复杂,包括心电图、DSA(血管造影)、超声、核医学、病理,就连口腔和CT都有影像。所以,如何在医院里如何以病人为中心,统一调度所有影像数据,就是一个不小的挑战。
2012年,医院建立影像数据中心,在这个系统里,医生可以调阅一个病人的所有的影像数据。平台实现了统一管理、存储、调阅和展现。
运营数据中心
2008年起,北大人民医院开始对所有后台运营的数据建立统一的管理系统。此后陆续建成了固定资产管理、物流采购管理、物流库存管理、统一采购平台、财务应付管理、财务应收管理、人力资源管理和外围业务运营系统等。
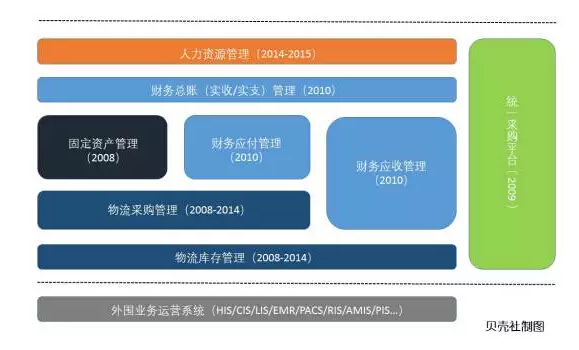
由于固定资产管理和药品、低值和高值耗材的管理占了医院流水的60%多,我们决定统一用物流管理平台来管控;人力资源管理系统则主要管理薪酬、五险一金、奖金绩效等;统一的B2B平台则实现了对外自动化的采购流程—— 无需人工,平台自动和供应商进行供应链的整合。
运营管理系统非常重要,是整个医院后台支撑的基石。
三大信息模块数据的变现思路
我一直提倡要从需求端出发。医生的科研需求大致可以分为八大类:风险预测模型、人群健康管理、药物及器械安全型监测、疾病及治疗的异质性分析、精准医疗及临床决策、医疗质量及行为评估、公共健康和研究应用。
目前,我们能够看到的应用主要有三件事:
· 用数据形成临床流程和临床指南
· 用智能科研平台改进医学标准
· 用数据驱动科学的医院管理
大数据如何辅助科研?
要让大数据真正服务于科研,必须要思考的问题是,如何把大量的临床资料和临床科研整合在一起,将数据转化为解决临床需求的知识。大数据科研平台的核心功能,就是提供一个平台,运用各种大数据技术和传统的统计学方法等,为医生和科研人员提供一个工具。
大数据带来的真正意义是,通过历史的数据发现新的规律,做没有假设的研究。
科研、IT和数字科学三方合作的基本逻辑是:首先,也是最重要的一点,医生在长期的临床工作实践中,总结、思考后,提出科研问题和目标;第二,基于这个目标,医生提出需要哪些数据,并从所有数据中确定所需要的临床条件;最后,技术人员根据这些需求把数据整理好,最终达到支持临床研究的目的。
我们医院曾经有一个心内科专家提出,想要做出心衰病人出院1年后再入院发生率的预测模型,了解其影响因素。因为心衰病人基数大,且住院期间发生的费用是其医疗总费用的60%,从卫生经济学角度上说,这个研究非常有意义—— 减少再入院率是减少医疗费用的关键因素。
对于这个项目而言,第一件事就是确定研究对象。技术人员根据ICD诊断为心衰的指数,筛选出了自2010年到2015年间的14985份疑似病历,但ICD只能作为初选的纳入标准。
确定真正的研究对象,要使用改良的Framingham心力衰竭诊断标准进行复核。要从每份疑似病历中提取症状、体征、诊断、病史、辅助检查和治疗等数据,并通过数据分析把有差异的病历都抽取出来。
评估下来,如果靠人来筛选的话,每份病历需要耗费半小时,以每天连续工作10小时、无节假日计算,需2.05年的时间。这样的投入成本让研究看起来不可操作。
并且,已有的主客观病历数据,都是非结构化的,不可以直接被使用。
这种情况下,北大人民医院的科研数据平台nova就发挥作用了。
平台首先做的就是做自然语言分析,其使用NLP(将非结构化数据进行结构化处理的一种分词方法),将自然语言进行全切分,比如将“他说的确实在理”这句话,切分为“他”、“说”、“的确”、“确实”“实在”、“在理”。
将院内CDR(如医院DB,HIS, LIS, DBn等),院外客观数据(健康管理智能硬件、体检、基因检测、公共职能)和院外主观数据(生活量表、随访等)等结构化之后,nova就可以做一个数据处理层了,也就是把所有的数据打上标签,再用一系列的大数据技术,把浩如烟海的原始的临床数据变成可搜索的数据。
在此基础之上,还有一个数据应用平台,这个平台上搭载了科研系统分析平台、项目管理平台(多中心管理、患者管理、疾病管理、随访管理系统、eCRF管理系统)等,以这种方式给医生提供科研工具。
Nova只花了1周左右的时间,就提取了心衰再入院及非再入院患者的特征变量,找到了研究所需的所有数据—— 一共纳入1103例心衰患者,研究变量123个,共135669个变量。
通过“随机森林算法”,技术人员找到年龄、糖尿病、高脂血症、缺血性脑血管病、慢性阻塞性肺病、舒张压、血清白蛋白、血清钠、Ln血胆固醇和出院带β受体阻滞剂等10个可能影响患者未来再入院率的指标,然后做了一个比例风险的模型,把各个因素加权后变成一个公式。
最后回到临床,这个公式在新进病历中得到了很好的验证。
截至今年7月底, nova上有科研统计需求101个,涉及临床科室35个(北大人民医院临床科室数44个,占比80%),已有用户数256人(北大人民医院医生数945人,占比达27.1%),7月单月,医生查询次数达到2718次。
我们做科研数据平台nova有4个基本逻辑:
· 无论结构化还是非结构化,必须要先有数据。
· 数据需要整合。
· 技术永远不是最大的问题,技术只是一个支撑。
· 以应用为导向。
实践发现,科研数据平台能够大大提高科研效率;不仅如此,平台还革新了传统的有假设驱动的研究方法,创造了无假设的研究方式;最后,好的研究想法都是临床中发掘出来的,科研工具用完之后还得回到临床,完成PDCA的循环反馈过程。


